

Khi nhắc đến độ chính xác tuyệt đối trong quang học và đo lường công nghiệp, cái tên đầu tiên xuất hiện trong tâm trí các kỹ sư và nhà khoa học trên toàn thế giới chính là ZEISS (Carl Zeiss). Trải qua hơn 175 năm tồn tại và phát triển, từ một xưởng cơ khí chính xác nhỏ bé tại thành phố Jena (Đức) cho đến một tập đoàn công nghệ toàn cầu, ZEISS đã không ngừng định hình lại cách chúng ta nhìn nhận thế giới và kiểm soát chất lượng sản phẩm.

Chỉ trong vòng chưa đầy 24 tiếng kể từ khi Renishaw tung ra teaser đầu tiên về dòng sản phẩm mới mang tên RMP400S, giới kỹ sư đo lường và gia công cơ khí chính xác toàn cầu đã thực sự được một phen xôn xao. Là một kỹ sư Quản lý Chất lượng nhiều năm bám trụ tại xưởng sản xuất, tôi hiểu rằng mỗi khi Renishaw ra mắt một thiết bị mới, đó không chỉ là sự nâng cấp phần cứng đơn thuần, mà là một sự dịch chuyển về triết lý sản xuất.

Gần đây, giới công nghệ đo lường công nghiệp đã được một phen xôn xao khi Renishaw chính thức giới thiệu dòng sản phẩm hoàn toàn mới: Đầu đo RUP60 độ dày bằng sóng siêu âm lắp trực tiếp trên máy công cụ.
NVIDIA đã phát triển một cách tiếp cận mới để đào tạo các mô hình mạng đối xứng tạo sinh (generative adversarial networks - GANs). Phương pháp này yêu cầu lượng dữ liệu đầu vào ít hơn đáng kể so với các phương pháp phổ biến hiện nay. Trong khi chất lượng đào tạo vẫn được đảm bảo tuyệt đối.
Nếu bạn chưa biết thì GAN là hệ thống AI gồm 2 phần riêng biệt:
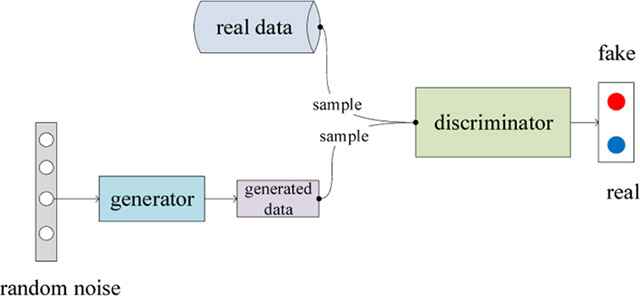
Công nghệ GAN
Các hệ thống GAN đã từng được áp dụng trong nhiều tác vụ chuyên sâu như chuyển đổi chú thích thành các câu chuyện theo từng bối cảnh, đặc biệt là tạo ra những bức ảnh, video nhân tạo với độ chân thực cực cao.
Về cơ bản, để có thể tạo ra các kết quả đáng tin cậy với sự nhất quán cao, các mô hình GAN truyền thống sẽ yêu cầu tối thiểu từ 50.000 đến 100.000 hình ảnh làm dữ liệu đào tạo đầu vào. Nếu lượng dữ liệu đào tạo quá ít, mô hình GAN có xu hướng gặp phải một vấn đề gọi là “overfitting”. Trong trường hợp này, Mạng phân biệt (Discriminative network) sẽ không có đủ cơ sở để huấn luyện cũng như tương tác với Mạng sinh (Generative network) một cách hiệu quả.
Trí tuệ nhân tạo đã có thể viết được hẳn một bài báo chỉ từ vài thông tin
Trước đây, phương pháp phổ biến mà các nhà nghiên cứu AI thường dùng để cố gắng giải quyết vấn đề thiếu dữ liệu đào tạo là sử dụng một kỹ thuật có tên gọi “tăng cường dữ liệu” (data augmentation). Sử dụng thuật toán hình ảnh làm ví dụ một lần nữa, trong trường hợp không có đủ dữ liệu đào tạo cần thiết, các chuyên gia sẽ cố gắng giải quyết vấn đề bằng cách tạo ra những bản sao "méo mó" của các hình ảnh có sẵn, chẳng hạn như cắt, xoay hoặc lật ảnh một hình ảnh gốc để tạo ra nhiều hình ảnh khác làm dữ liệu đào tạo bổ sung. Ý tưởng ở đây là không để mô hình GAN nhìn thấy cùng một hình ảnh chính xác hai lần.
Tuy nhiên, vấn đề với phương pháp này là có thể khiến GAN học được cách bắt chước sự thay đổi không tự nhiên của dữ liệu đào tạo, thay vì tạo ra một cái gì đó mới. Để giải quyết vấn đề, NVIDIA đã phát triển một phương pháp mới có tên gọi “Tăng cường Phân biệt Thích ứng (ADA). Trong đó cốt lõi vẫn là kỹ thuật tăng cường dữ liệu, nhưng triển khai theo cách thích ứng. Thay vì “bóp méo” bừa bãi hình ảnh trong toàn bộ quá trình đào tạo, ADA thực hiện quá trình này một cách chọn lọc và vừa đủ để GAN vẫn đạt hiệu suất tốt nhất.
Kết quả khả quan của phương pháp đào tạo ADA mang đến nhiều ý nghĩa quan trọng trong lĩnh vực trí tuệ nhân tạo. Bởi khâu thu thập đủ lượng dữ liệu đào tạo cần thiết nghe tưởng chừng đơn giản nhưng trên thực tế rất khó khăn. Chẳng hạn đối với một mô hình AI sáng tác văn học, bản sẽ không cần phải lo thiếu dữ liệu đào tạo đầu vào. Tuy nhiên trong trường hợp của một thuật toán AI chuyên phát hiện chứng rối loạn thần kinh hiếm gặp, chỉ riêng việc thu thập đủ dữ liệu đào tạo thôi đã là vấn đề lớn. Một mô hình GAN được đào tạo với cách tiếp cận ADA của NVIDIA có thể giải quyết vấn đề trên.
Nguồn: quantrimang.com
(84) 896 555 247